和休の会社では、パソコンのユーザー名を、苗字をローマ字で表記したものとしています。
和休は会社でパソコンの管理者をしているのですが、ユーザー名のローマ字表記が、微妙に統一されていないことに気づきました。
例えば、「し」という読みのローマ字。「SI」と入力されているもの、「SHI」と入力されているものが存在するといった、「ゆらぎ」があるんですね。
- TAKAHASI
- TAKAHASHI
ローマ字沼
以前、機器の入れ替えを期に統一してしまおうと考え、ローマ字を調べてみたことがあるのです。
すると、さまざまなルールが存在することに気づきました。
小学校の時にローマ字を習いますが、「訓令式」というルールで教わります。「し」は「si」と表記します。
対して、英語表記に近いのが「ヘボン式」と呼ばれるもので、「し」は「shi」と表記します。
さらに、一口に訓令式、ヘボン式といっても、時代や必要性に合わせて変化してきているので、統一された規格は存在しないといってもいいでしょう。
唯一、「ISO 3602」が国際規格として認められているそうですが、日本国内で普及しているとは言えません。
本記事で、ローマ字のルールを語ることは割愛しますが、いずれかのルールを採用しないと前に進めません。
外務省ヘボン式を使って変換します
和休が目を付けたのが、外務省がパスポートに名前を記すときのルールである方式、「外務省ヘボン式」とか「パスポート式」と呼ばれるものです。
伸ばす音「-(ハイフン)」は省略される、すべて大文字で表記する、といった特徴があります。
ヘボン式ローマ字綴方表
ア A イ I ウ U エ E オ O カ KA キ KI ク KU ケ KE コ KO サ SA シ SHI ス SU セ SE ソ SO タ TA チ CHI ツ TSU テ TE ト TO ナ NA ニ NI ヌ NU ネ NE ノ NO ハ HA ヒ HI フ FU ヘ HE ホ HO マ MA ミ MI ム MU メ ME モ MO ヤ YA ユ YU ヨ YO ラ RA リ RI ル RU レ RE ロ RO ワ WA ヰ I ヱ E ヲ O ン N(M) ガ GA ギ GI グ GU ゲ GE ゴ GO ザ ZA ジ JI ズ ZU ゼ ZE ゾ ZO ダ DA ヂ JI ヅ ZU デ DE ド DO バ BA ビ BI ブ BU ベ BE ボ BO パ PA ピ PI プ PU ペ PE ポ PO キャ KYA キュ KYU キョ KYO シャ SHA シュ SHU ショ SHO チャ CHA チュ CHU チョ CHO ニャ NYA ニュ NYU ニョ NYO ヒャ HYA ヒュ HYU ヒョ HYO ミャ MYA ミュ MYU ミョ MYO リャ RYA リュ RYU リョ RYO ギャ GYA ギュ GYU ギョ GYO ジャ JA ジュ JU ジョ JO ビャ BYA ビュ BYU ビョ BYO ピャ PYA ピュ PYU ピョ PYO ※参考
シェ SHIE チェ CHIE ティ TEI ニィ NII ニェ NIE ファ FUA フィ FUI フェ FUE フォ FUO ジェ JIE ディ DEI デュ DEYU ウィ UI ウェ UE ウォ UO ヴァ BA ヴィ BI ヴ BU ヴェ BE ヴォ BO ヴァ BUA ヴィ BUI ヴェ BUE ヴォ BUO ※注意 「ヴァ:VA」「ヴィ:VI」「ヴ:VU」「ヴェ:VE」「ヴォ:VO」は使用不可
【ヘボン式ローマ字表記へ変換する際の注意事項】
外務省のホームページから引用
- 撥音:B、M、Pの前の「ん」は、NではなくMで表記します。
例:難波(ナンバ)NAMBA、本間(ホンマ)HOMMA、三瓶(サンペイ)SAMPEI- 促音:子音を重ねて表記します。
例:服部(ハットリ)HATTORI、吉川(キッカワ)KIKKAWA
ただし、チ(CHI)、チャ(CHA)、チュ(CHU)、チョ(CHO)音の前には「T」を表記します。
例:発地(ホッチ)HOTCHI、八丁(ハッチョウ)HATCHO- 長音:OやUは記入しません。
※長音表記を希望する場合には、下記【ヘボン式によらないローマ字氏名表記】を参照してください。
「―」を省略する場合
例:ニーナ(ニーナ)NINA、シーナ(シーナ)SHINA、サリー(サリー)SARI
「イ」を省略しない場合
例:新菜(ニイナ)NIINA、しいな(シイナ)SHIINA、さりい(サリイ)SARII
「ウ」を含む長音「ウウ」の場合(「UU」は表記しません。)
例:日向(ヒュウガ)HYUGA、裕貴(ユウキ)YUKI、優子(ユウコ)YUKO
「オ」を含む長音「オウ」の場合(「OU」は表記しません。)
例:幸太(コウタ)KOTA、洋子(ヨウコ)YOKO、亮子(リョウコ)RYOKO
「オ」を含む長音「オオ」の場合(「OO」は表記しません。)
例:大野(オオノ)ONO、大河内(オオコウチ)OKOCHI、大西(オオニシ)ONISHI
末尾が「オオ」音で、ヨミカタが「オ」の場合(「OO」と表記します。)
例:妹尾(セノオ)SENOO、高藤(タカトオ)TAKATOO、横尾(ヨコオ)YOKOO
末尾が「オウ」音で、ヨミカタが「ウ」の場合(「OU」とは表記しません。)
例:伊藤(イトウ)ITO、高藤(タカトウ)TAKATO、御園生(ミソノウ)MISONO- 「ヴ」のつく氏名例
例:ヴィヴィアン(ヴィヴィアン)BUIBUIAN 又はBIBIAN、
ヴォードレール(ヴォードレール)BUODORERU 又はBODORERU
Access VBAによるローマ字変換
これらのルールを踏まえて、AccessのVBAで、よみがなのローマ字変換に挑戦してみました。
まず、カタカナとローマ字の対比表をテーブルとして作成します。
テーブル名「変換表 」
| カタカナ | ローマ字 |
|---|---|
| ア | A |
| イ | I |
| ウ | U |
| ヴ | BU |
| ヴァ | BA |
| ヴァ | BUA |
| ウィ | UI |
| ヴィ | BI |
| ヴィ | BUI |
| ウェ | UE |
| ヴェ | BE |
| ヴェ | BUE |
| ウォ | UO |
| ヴォ | BO |
| ヴォ | BUO |
| エ | E |
| オ | O |
| カ | KA |
| ガ | GA |
| キ | KI |
| ギ | GI |
| キャ | KYA |
| ギャ | GYA |
| キュ | KYU |
| ギュ | GYU |
| キョ | KYO |
| ギョ | GYO |
| ク | KU |
| グ | GU |
| ケ | KE |
| ゲ | GE |
| コ | KO |
| ゴ | GO |
| サ | SA |
| ザ | ZA |
| シ | SHI |
| ジ | JI |
| シェ | SHIE |
| ジェ | JIE |
| シャ | SHA |
| ジャ | JA |
| シュ | SHU |
| ジュ | JU |
| ショ | SHO |
| ジョ | JO |
| ス | SU |
| ズ | ZU |
| セ | SE |
| ゼ | ZE |
| ソ | SO |
| ゾ | ZO |
| タ | TA |
| ダ | DA |
| チ | CHI |
| ヂ | JI |
| チェ | CHIE |
| チャ | CHA |
| チュ | CHU |
| チョ | CHO |
| ツ | TSU |
| ヅ | ZU |
| テ | TE |
| デ | DE |
| ティ | TEI |
| ディ | DEI |
| デュ | DEYU |
| ト | TO |
| ド | DO |
| ナ | NA |
| ニ | NI |
| ニィ | NII |
| ニェ | NIE |
| ニャ | NYA |
| ニュ | NYU |
| ニョ | NYO |
| ヌ | NU |
| ネ | NE |
| ノ | NO |
| ハ | HA |
| バ | BA |
| パ | PA |
| ヒ | HI |
| ビ | BI |
| ピ | PI |
| ヒャ | HYA |
| ビャ | BYA |
| ピャ | PYA |
| ヒュ | HYU |
| ビュ | BYU |
| ピュ | PYU |
| ヒョ | HYO |
| ビョ | BYO |
| ピョ | PYO |
| フ | FU |
| ブ | BU |
| プ | PU |
| ファ | FUA |
| フィ | FUI |
| フェ | FUE |
| フォ | FUO |
| ヘ | HE |
| ベ | BE |
| ペ | PE |
| ホ | HO |
| ボ | BO |
| ポ | PO |
| マ | MA |
| ミ | MI |
| ミャ | MYA |
| ミュ | MYU |
| ミョ | MYO |
| ム | MU |
| メ | ME |
| モ | MO |
| ヤ | YA |
| ユ | YU |
| ヨ | YO |
| ラ | RA |
| リ | RI |
| リャ | RYA |
| リュ | RYU |
| リョ | RYO |
| ル | RU |
| レ | RE |
| ロ | RO |
| ワ | WA |
| ヰ | I |
| ヱ | E |
| ヲ | O |
| ン | N |
自作関数「romaCONV」
次に、標準モジュールを新規作成し、次のコードを貼り付けてください。
Option Compare Database
Option Explicit
Function romaCONV(kana As String) As String
Dim moto As String '変換前のかな
Dim nagasa As Long '変換前のかなの文字数
Dim henkanmae() As String '変換前の文字
Dim henkango() As String '変換後の文字
Dim romaji As String 'ローマ字
'変換前のかなを全角カタカナに変換する
moto = StrConv(kana, vbKatakana)
'変換前のかなの文字数を取得する
nagasa = Len(moto)
'文字数を配列の最大値にセットする
ReDim henkanmae(nagasa)
ReDim henkango(nagasa)
Dim LP_cnt As Long 'ループカウンター
For LP_cnt = 1 To nagasa
'拗音のとき
If Mid(moto, LP_cnt, 1) = "ァ" Or _
Mid(moto, LP_cnt, 1) = "ィ" Or _
Mid(moto, LP_cnt, 1) = "ゥ" Or _
Mid(moto, LP_cnt, 1) = "ェ" Or _
Mid(moto, LP_cnt, 1) = "ォ" Or _
Mid(moto, LP_cnt, 1) = "ャ" Or _
Mid(moto, LP_cnt, 1) = "ュ" Or _
Mid(moto, LP_cnt, 1) = "ョ" Then
'ひとつ前の配列の文字に追加する
henkanmae(LP_cnt - 1) = henkanmae(LP_cnt - 1) & Mid(moto, LP_cnt, 1)
End If
henkanmae(LP_cnt) = Mid(moto, LP_cnt, 1)
Next LP_cnt
'DLOOKUP関数を用いてローマ字を取得し、その字を変数henkangoに代入する
For LP_cnt = 1 To nagasa
'促音:子音を重ねて表記します。
If Mid(moto, LP_cnt, 1) = "ッ" Then
'文末が「ッ」で終わるときは変換しない
If LP_cnt + 1 <= nagasa Then henkango(LP_cnt) = Left(Nz(DLookup("ローマ字", "変換表", "カタカナ='" & henkanmae(LP_cnt + 1) & "'"), ""), 1)
Else
henkango(LP_cnt) = Nz(DLookup("ローマ字", "変換表", "カタカナ='" & henkanmae(LP_cnt) & "'"), "")
End If
romaji = romaji & henkango(LP_cnt)
Next LP_cnt
'撥音:B、M、Pの前の「ん」は、NではなくMで表記します。
romaji = Replace(romaji, "NB", "MB")
romaji = Replace(romaji, "NM", "MM")
romaji = Replace(romaji, "NP", "MP")
'促音の例外:チ(CHI)、チャ(CHA)、チュ(CHU)、チョ(CHO)音の前には「T」を表記します。
romaji = Replace(romaji, "CCHI", "TCHI")
romaji = Replace(romaji, "CCHA", "TCHA")
romaji = Replace(romaji, "CCHU", "TCHU")
romaji = Replace(romaji, "CCHO", "TCHO")
'「ウ」を含む長音「ウウ」の場合(「UU」は表記しません。)
romaji = Replace(romaji, "UU", "U")
'「オ」を含む長音「オウ」の場合(「OU」は表記しません。)
romaji = Replace(romaji, "OU", "O")
'「オ」を含む長音「オオ」の場合(「OO」は表記しません。)
'末尾が「オオ」音で、ヨミカタが「オ」の場合(「OO」と表記します。)
If Not Right(romaji, 2) = "OO" Then romaji = Replace(romaji, "OO", "O")
romaCONV = romaji
End Function
変換テスト
イミディエイトウィンドウで、関数のテストを行います。
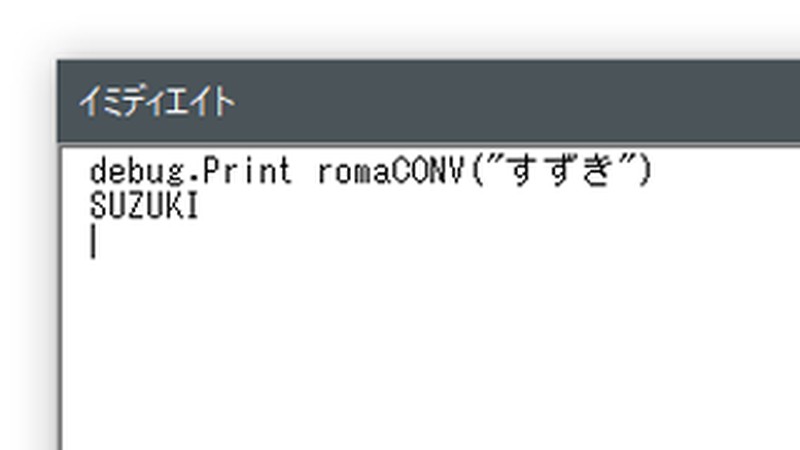
まず、特別なルールの無い文字をローマ字へ変換します。和休の乗っているバイクは、スズキ・バンディット1250Sですので、「すずき」を変換してみます。
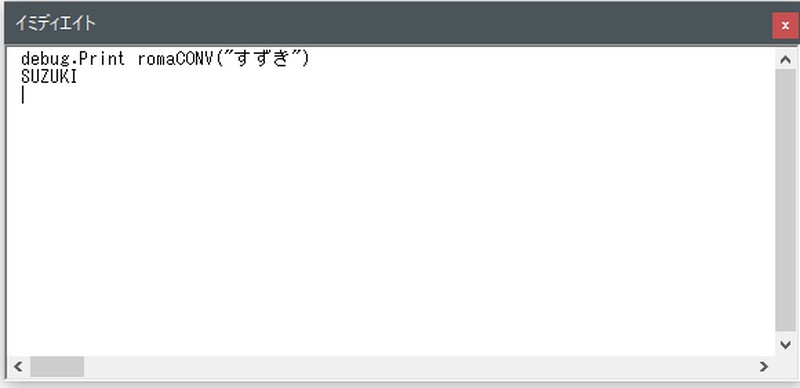
「SUZUKI」に変換できました。
続いて、外務省のホームページから【ヘボン式ローマ字表記へ変換する際の注意事項】で、特別な変換を行うとされる文字を試してみます。

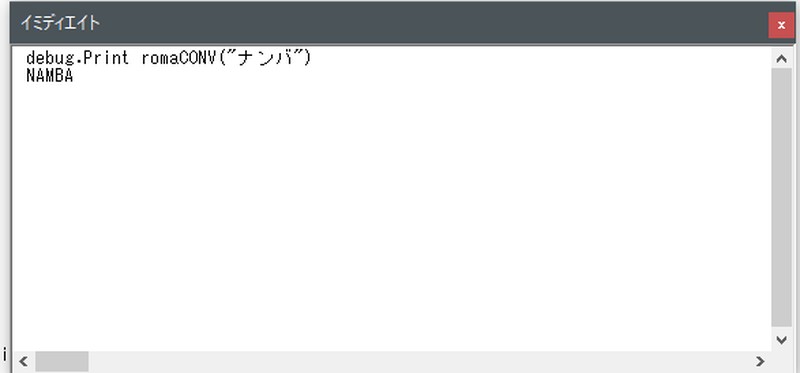
「難波」→「NAMBA」に変換できました。
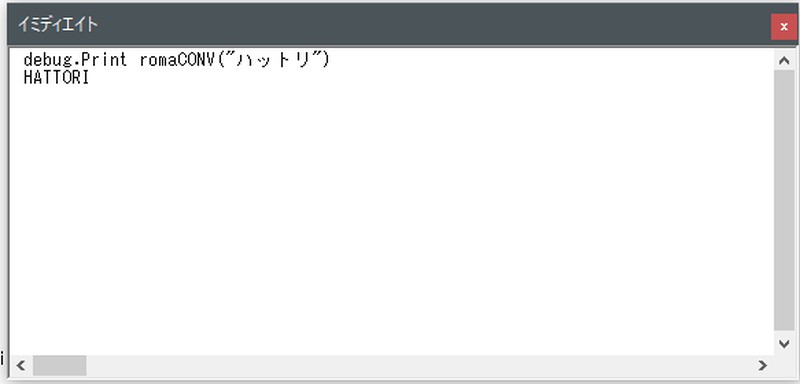
「服部」→「HATTORI」に変換できました。
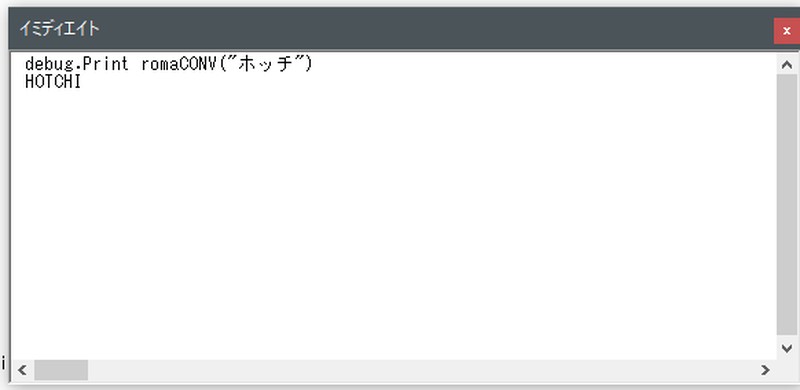
「発地」→「HOTCH」に変換できました。
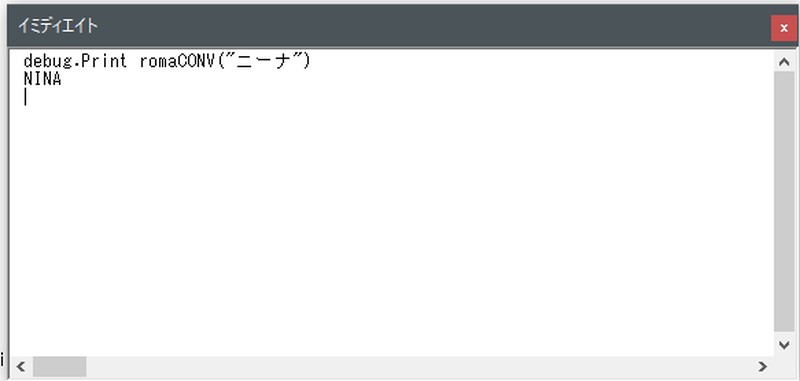
「ニーナ」→「NINA」に変換できました。
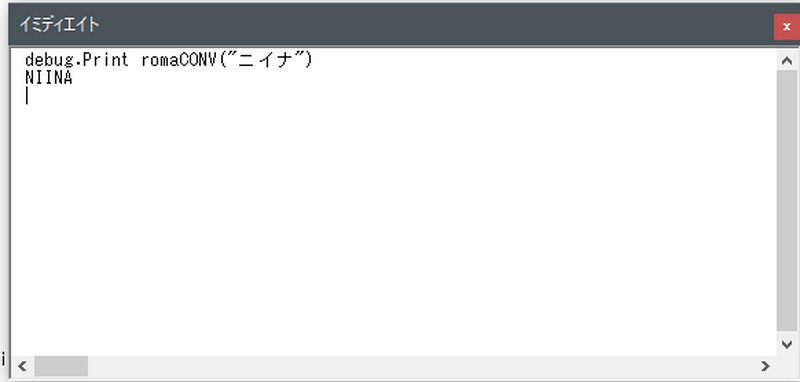
「新菜」→「NIINA」に変換できました。
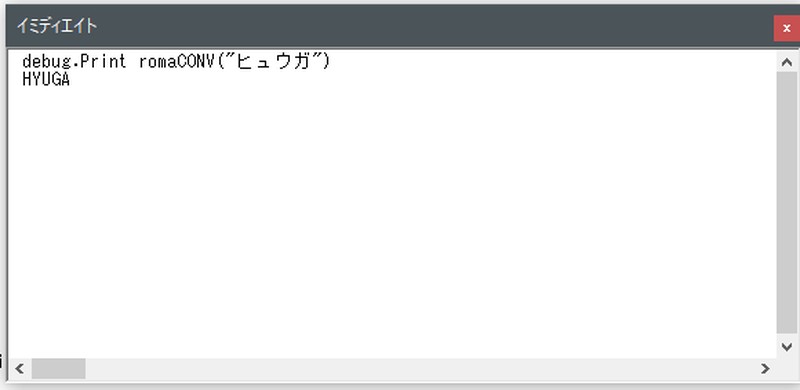
「日向」→「HYUGA」に変換できました。
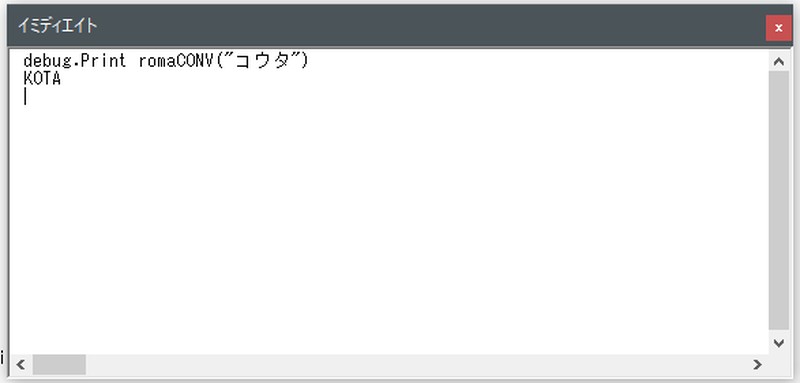
「幸太」→「KOTA」に変換できました。
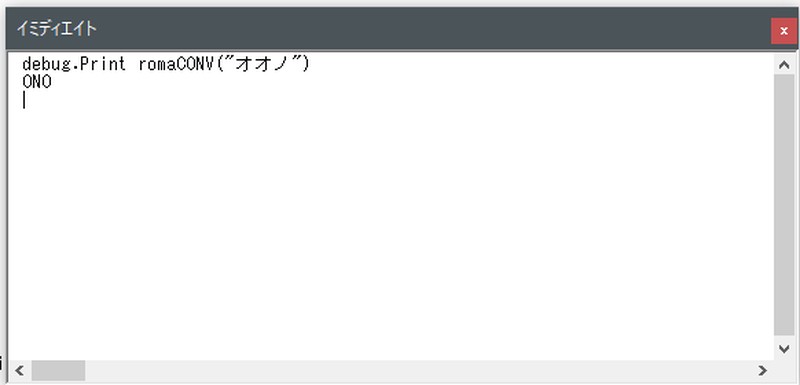
「大野」→「ONO」に変換できました。
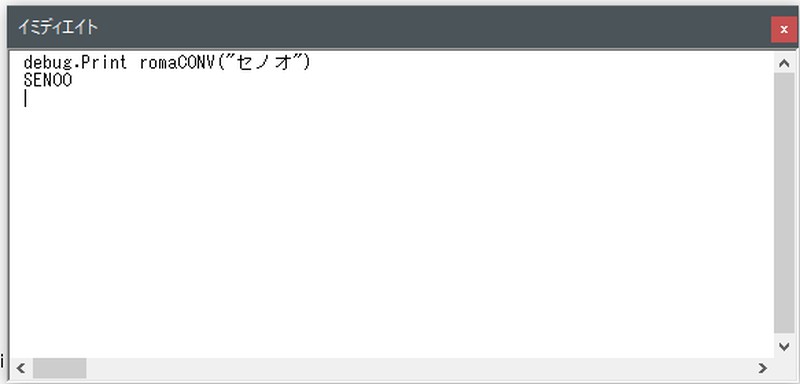
「妹尾」→「SENOO」に変換できました。
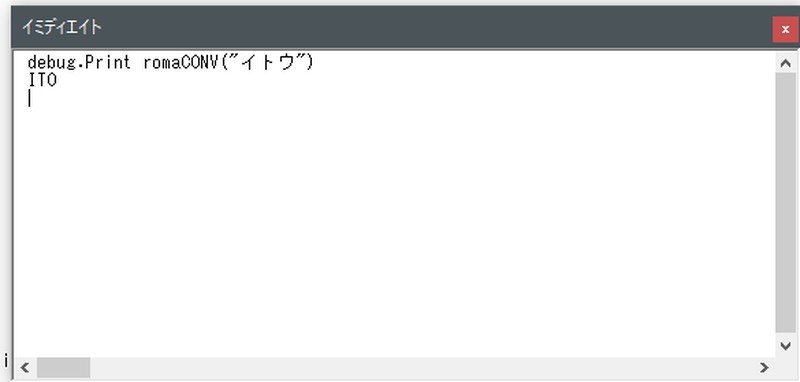
「伊藤」→「ITO」に変換できました。
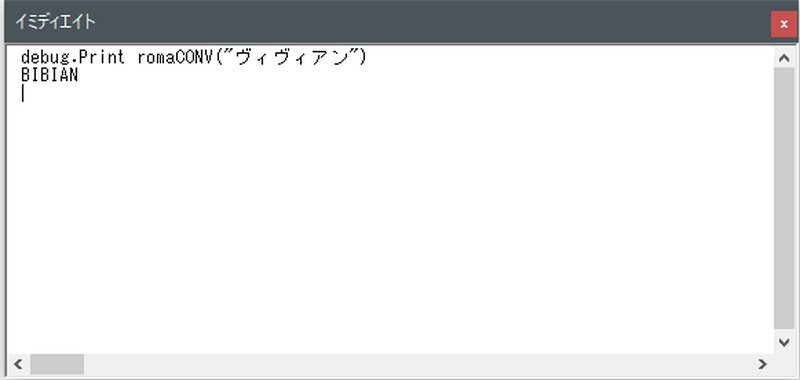
「ヴィヴィアン」→「BIBIAN」に変換できました。
すべて成功です!(b^ー°)

コメントをどうぞ!